Sorry,
*For example: (/var/log/graylog/elasticsearch/graylog.log)*
<
Loading Image...
>
<
Loading Image...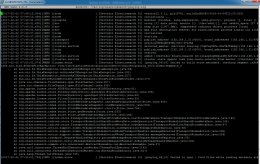
>
[2017-01-30 01:49:24,310][INFO ][cluster.metadata ] [Servidor
Graylog] [graylog_56] update_mapping [message]
[2017-01-30 01:49:24,591][INFO ][cluster.metadata ] [Servidor
Graylog] [graylog_56] update_mapping [message]
[2017-01-30 02:00:18,260][INFO ][cluster.metadata ] [Servidor
Graylog] [graylog_56] update_mapping [message]
[2017-01-30 02:24:34,321][INFO ][cluster.metadata ] [Servidor
Graylog] [graylog_56] update_mapping [message]
[2017-01-30 02:24:34,568][INFO ][cluster.metadata ] [Servidor
Graylog] [graylog_56] update_mapping [message]
[2017-01-30 05:44:38,282][INFO ][cluster.metadata ] [Servidor
Graylog] [graylog_56] update_mapping [message]
[2017-01-30 06:10:19,257][INFO ][cluster.metadata ] [Servidor
Graylog] [graylog_56] update_mapping [message]
[2017-01-30 06:25:32,267][INFO ][cluster.metadata ] [Servidor
Graylog] [graylog_56] update_mapping [message]
[2017-01-30 07:26:44,297][INFO ][cluster.metadata ] [Servidor
Graylog] [graylog_56] update_mapping [message]
[2017-01-30 07:26:48,272][INFO ][cluster.metadata ] [Servidor
Graylog] [graylog_56] update_mapping [message]
[2017-01-30 10:38:00,252][INFO ][cluster.metadata ] [Servidor
Graylog] [graylog_56] update_mapping [message]
[2017-01-30 16:19:33,278][INFO ][cluster.metadata ] [Servidor
Graylog] [graylog_56] update_mapping [message]
[2017-01-30 17:25:35,716][INFO ][cluster.metadata ] [Servidor
Graylog] [graylog_56] update_mapping [message]
[2017-01-30 18:03:43,270][INFO ][cluster.metadata ] [Servidor
Graylog] [graylog_56] update_mapping [message]
[2017-01-30 18:03:45,291][INFO ][cluster.metadata ] [Servidor
Graylog] [graylog_56] update_mapping [message]
[2017-01-30 18:04:17,286][INFO ][cluster.metadata ] [Servidor
Graylog] [graylog_56] update_mapping [message]
[2017-01-31 01:00:05,015][INFO ][cluster.metadata ] [Servidor
Graylog] [graylog_57] creating index, cause [api], templates
[graylog-internal], shards [4]/[1], mapping$
[2017-01-31 01:00:06,298][INFO ][cluster.routing.allocation] [Servidor
Graylog] Cluster health status changed from [RED] to [YELLOW] (reason:
[shards started [[graylog_57][0]$
[2017-01-31 01:00:07,427][INFO ][cluster.routing.allocation] [Servidor
Graylog] Cluster health status changed from [YELLOW] to [GREEN] (reason:
[shards started [[graylog_57][$
[2017-01-31 01:00:08,251][INFO ][cluster.metadata ] [Servidor
Graylog] [graylog_57] update_mapping [message]
[2017-01-31 01:00:08,254][INFO ][cluster.metadata ] [Servidor
Graylog] [graylog_57] update_mapping [message]
[2017-01-31 01:00:08,470][INFO ][cluster.metadata ] [Servidor
Graylog] [graylog_57] update_mapping [message]
[2017-01-31 01:00:08,737][INFO ][cluster.metadata ] [Servidor
Graylog] [graylog_57] update_mapping [message]
[2017-01-31 01:00:09,019][INFO ][cluster.metadata ] [Servidor
Graylog] [graylog_57] update_mapping [message]
[2017-01-31 01:00:09,403][INFO ][cluster.metadata ] [Servidor
Graylog] [graylog_57] update_mapping [message]
[2017-01-31 01:00:09,657][INFO ][cluster.metadata ] [Servidor
Graylog] [graylog_57] update_mapping [message]
[2017-01-31 01:00:10,278][INFO ][cluster.metadata ] [Servidor
Graylog] [graylog_57] update_mapping [message]
[2017-01-31 01:00:10,477][INFO ][cluster.metadata ] [Servidor
Graylog] [graylog_57] update_mapping [message]
[2017-01-31 01:00:18,255][INFO ][cluster.metadata ] [Servidor
Graylog] [graylog_57] update_mapping [message]
[2017-01-31 01:00:22,259][INFO ][cluster.metadata ] [Servidor
Graylog] [graylog_57] update_mapping [message]
[2017-01-31 01:00:34,326][INFO ][cluster.metadata ] [Servidor
Graylog] [graylog_57] update_mapping [message]
[2017-01-31 01:00:34,531][INFO ][cluster.metadata ] [Servidor
Graylog] [graylog_57] update_mapping [message]
[2017-01-31 01:00:34,535][INFO ][cluster.metadata ] [Servidor
Graylog] [graylog_57] update_mapping [message]
[2017-01-31 01:00:34,821][INFO ][cluster.metadata ] [Servidor
Graylog] [graylog_57] update_mapping [message]
[2017-01-31 01:00:34,824][INFO ][cluster.metadata ] [Servidor
Graylog] [graylog_57] update_mapping [message]
[2017-01-31 01:00:34,828][INFO ][cluster.metadata ] [Servidor
Graylog] [graylog_57] update_mapping [message]
[2017-01-31 01:00:35,055][INFO ][cluster.metadata ] [Servidor
Graylog] [graylog_57] update_mapping [message]
El jueves, 2 de febrero de 2017, 12:57:03 (UTC+1), Jochen Schalanda
Post by Jochen SchalandaHi Aitor,
http://docs.graylog.org/en/2.1/pages/configuration/file_location.html#deb-package
Cheers,
Jochen
--
You received this message because you are subscribed to the Google Groups "Graylog Users" group.
To unsubscribe from this group and stop receiving emails from it, send an email to graylog2+***@googlegroups.com.
To view this discussion on the web visit https://groups.google.com/d/msgid/graylog2/f6c48475-38b9-40f1-bf87-e5b65abdc69d%40googlegroups.com.
For more options, visit https://groups.google.com/d/optout.



